Kanban 教程
AigenLabs Kanban 系统所设计的四个使用场景的完整演示,需在浏览器中打开 dashboard。如果你还没有阅读 Kanban 概述,请先从那里开始——本文假设你已了解 task(任务)、run(运行)、assignee(负责人)和 dispatcher(调度器)的概念。
准备工作
aigenlabs kanban init # 可选;首次执行 `aigenlabs kanban <任何命令>` 会自动初始化
aigenlabs dashboard # 在浏览器中打开 http://127.0.0.1:9119
# 点击左侧导航栏中的 Kanban
dashboard 是你观察系统最便捷的地方。dispatcher 生成的 agent worker 不会看到 dashboard 或 CLI——它们通过专用的 kanban_* 工具集(kanban_show、kanban_list、kanban_complete、kanban_block、kanban_heartbeat、kanban_comment、kanban_create、kanban_link、kanban_unblock)来操作看板。三个界面——dashboard、CLI、worker 工具——都通过同一个每看板独立的 SQLite 数据库(默认看板为 ~/.aigenlabs/kanban.db,后续创建的任意看板为 ~/.aigenlabs/kanban/boards/<slug>/kanban.db)进行路由,因此无论变更来自哪一侧,每个看板的数据始终一致。
本教程全程使用 default 看板。如果你需要多个隔离队列(每个项目/仓库/领域一个),请参阅概述中的看板(多项目)——相同的 CLI/dashboard/worker 流程适用于每个看板,且 worker 在物理上无法看到其他看板上的任务。
在本教程中,标注为 bash 的代码块是你运行的命令。 标注为 # worker tool calls 的代码块是生成的 worker 模型发出的工具调用——展示在这里是为了让你能端到端地了解整个循环,而不是让你自己去运行它们。
看板概览
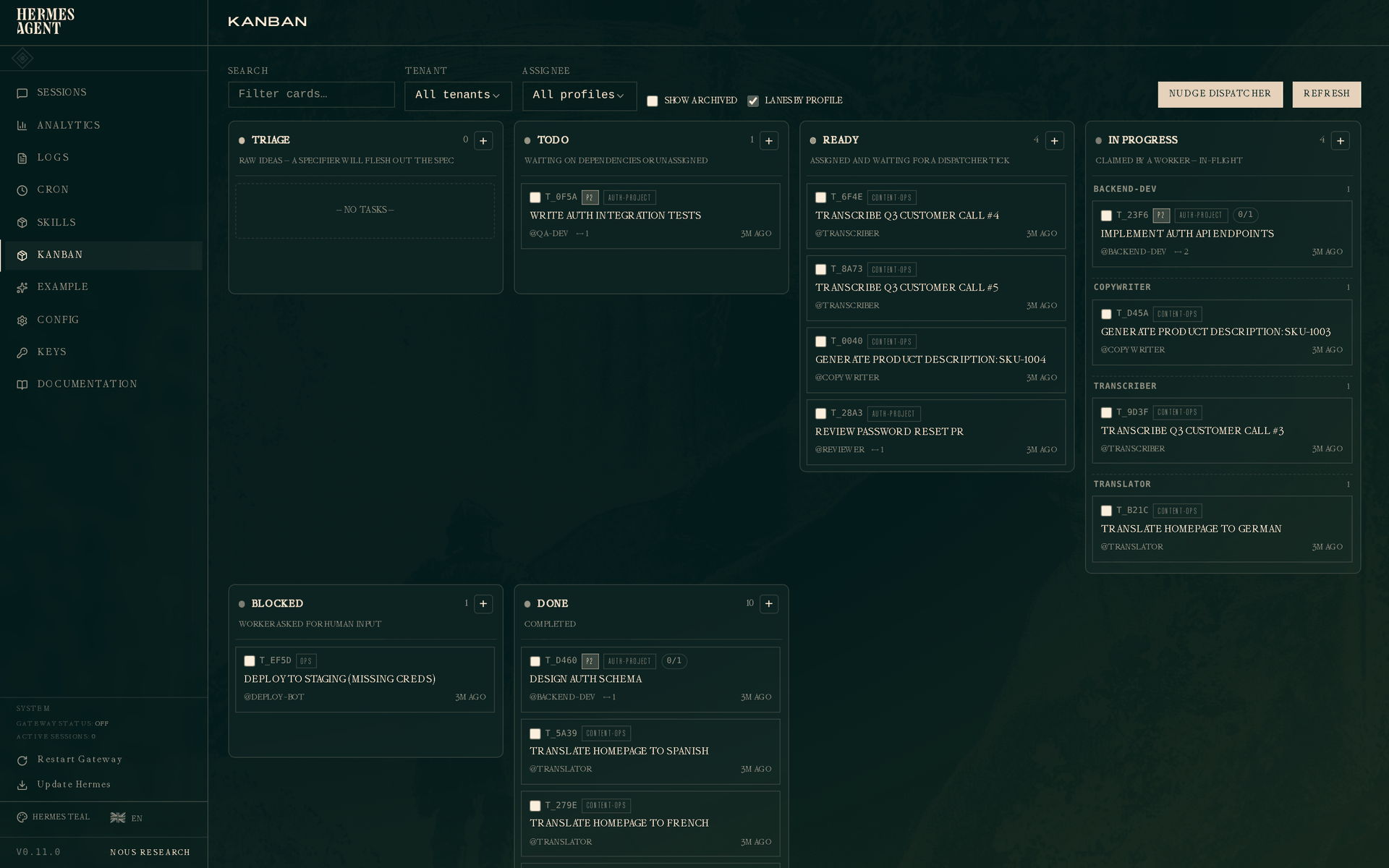
从左到右共六列:
- Triage(分类) — 原始想法。默认情况下,dispatcher 会对此处的任务自动运行分解器(orchestrator 驱动的扇出):它读取你的 profile 名册和描述,生成一张子任务图,将任务路由给最合适的专家,同时保持原始任务作为父任务存活,以便在所有子任务完成后 orchestrator 重新唤醒来判断完成情况。点击 kanban 页面顶部的 Orchestration: Auto/Manual 切换按钮来切换模式。在 Manual 模式下(或没有 orchestrator profile 的配置中),点击卡片上的 ⚗ Decompose,或运行
aigenlabs kanban decompose <id>//kanban decompose <id>。对于不需要扇出的单个任务,✨ Specify 会进行一次性规格重写(目标、方法、验收标准)并将任务提升到todo。在config.yaml的auxiliary.kanban_decomposer和auxiliary.triage_specifier下配置相关模型。参见主 Kanban 指南中的自动与手动编排。 - Todo(待办) — 已创建但等待依赖项,或尚未分配。
- Ready(就绪) — 已分配,等待 dispatcher 认领。
- In progress(进行中) — worker 正在主动执行任务。开启"Lanes by profile"(默认开启)时,此列按负责人分组,让你一眼看出每个 worker 正在做什么。
- Blocked(阻塞) — worker 请求人工输入,或熔断器触发。
- Done(完成) — 已完成。
顶部栏提供搜索、租户和负责人的筛选器,以及 Lanes by profile 切换按钮和 Nudge dispatcher 按钮——后者会立即执行一次调度 tick,而无需等待守护进程的下一个间隔。点击任意卡片会在右侧打开其详情抽屉。
平铺视图
如果 profile 泳道显示过于嘈杂,关闭"Lanes by profile",In Progress 列会折叠为按认领时间排序的单一平铺列表:
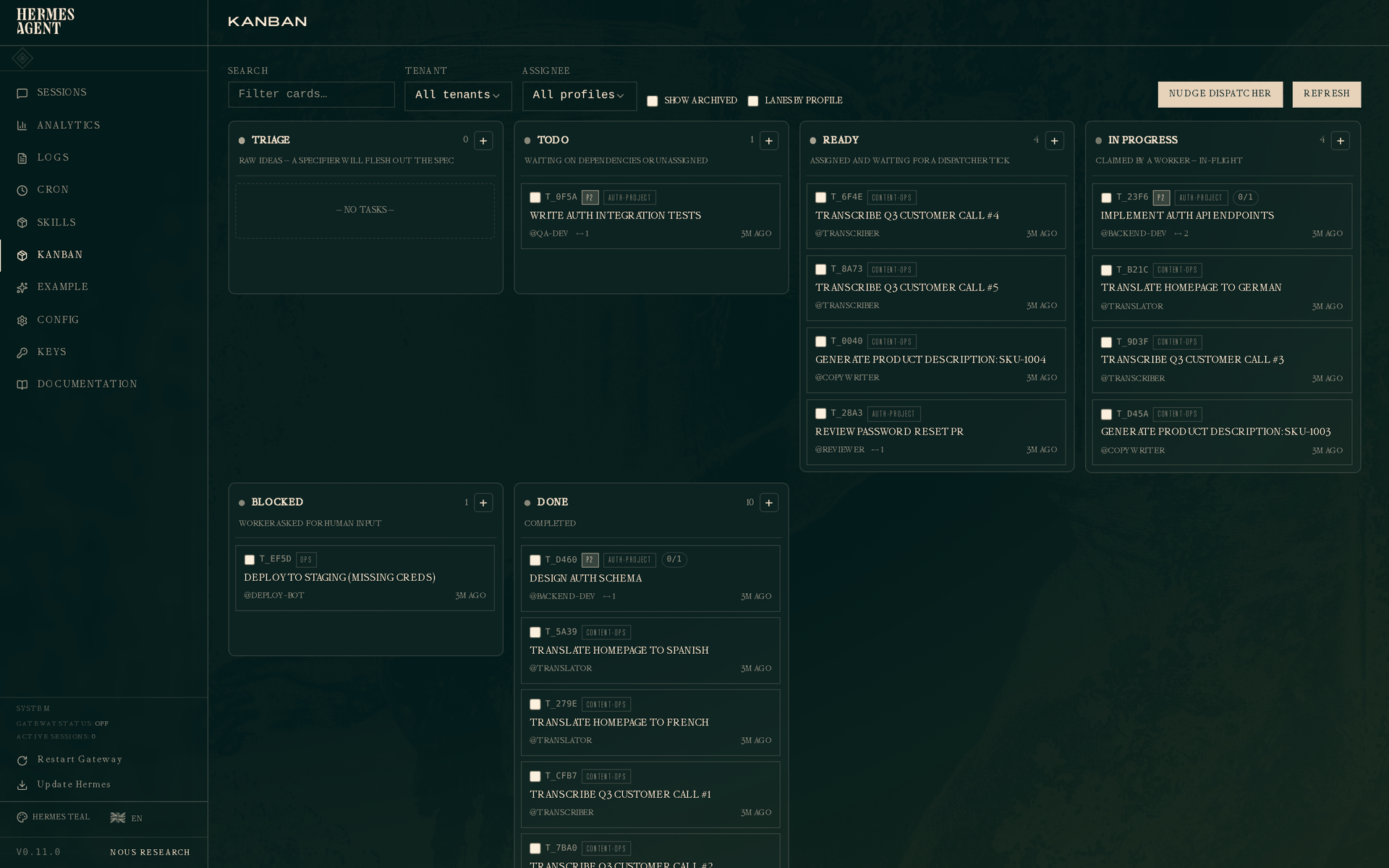
场景一 — 独立开发者交付功能
你正在开发一个功能。经典流程:设计 schema、实现 API、编写测试。三个任务,具有父→子依赖关系。
SCHEMA=$(aigenlabs kanban create "Design auth schema" \
--assignee backend-dev --tenant auth-project --priority 2 \
--body "Design the user/session/token schema for the auth module." \
--json | jq -r .id)
API=$(aigenlabs kanban create "Implement auth API endpoints" \
--assignee backend-dev --tenant auth-project --priority 2 \
--parent $SCHEMA \
--body "POST /register, POST /login, POST /refresh, POST /logout." \
--json | jq -r .id)
aigenlabs kanban create "Write auth integration tests" \
--assignee qa-dev --tenant auth-project --priority 2 \
--parent $API \
--body "Cover happy path, wrong password, expired token, concurrent refresh."
由于 API 以 SCHEMA 为父任务,tests 以 API 为父任务,只有 SCHEMA 从 ready 状态开始。其他两个任务在 todo 中等待,直到其父任务完成。这正是依赖提升引擎在发挥作用——在有 API 可测试之前,不会有其他 worker 去接手测试编写工作。
在下一次 dispatcher tick 时(默认 60 秒,或点击 Nudge dispatcher 立即触发),backend-dev profile 会以 AIGENLABS_KANBAN_TASK=$SCHEMA 作为环境变量生成一个 worker。以下是该 worker 在 agent 内部的工具调用循环:
# worker tool calls — NOT commands you run
kanban_show()
# → 返回 title、body、worker_context、parents、prior attempts、comments
# (worker 读取 worker_context,使用终端/文件工具设计 schema,
# 编写迁移脚本,运行自身检查,提交——真正的工作在这里发生)
kanban_heartbeat(note="schema drafted, writing migrations now")
kanban_complete(
summary="users(id, email, pw_hash), sessions(id, user_id, jti, expires_at); "
"refresh tokens stored as sessions with type='refresh'",
metadata={
"changed_files": ["migrations/001_users.sql", "migrations/002_sessions.sql"],
"decisions": ["bcrypt for hashing", "JWT for session tokens",
"7-day refresh, 15-min access"],
},
)
kanban_show 默认将 task_id 设为 $AIGENLABS_KANBAN_TASK,因此 worker 无需知道自己的 id。kanban_complete 将 summary 和 metadata 写入当前 task_runs 行,关闭该 run,并将任务转换为 done——全部通过 kanban_db 以原子方式完成。
当 SCHEMA 进入 done 状态时,依赖引擎会自动将 API 提升为 ready。API worker 认领任务后,调用 kanban_show() 时会看到 SCHEMA 的 summary 和 metadata 附加在父任务交接信息中——因此它无需重新阅读冗长的设计文档就能了解 schema 的决策。
在看板上点击已完成的 schema 任务,抽屉会显示所有信息:
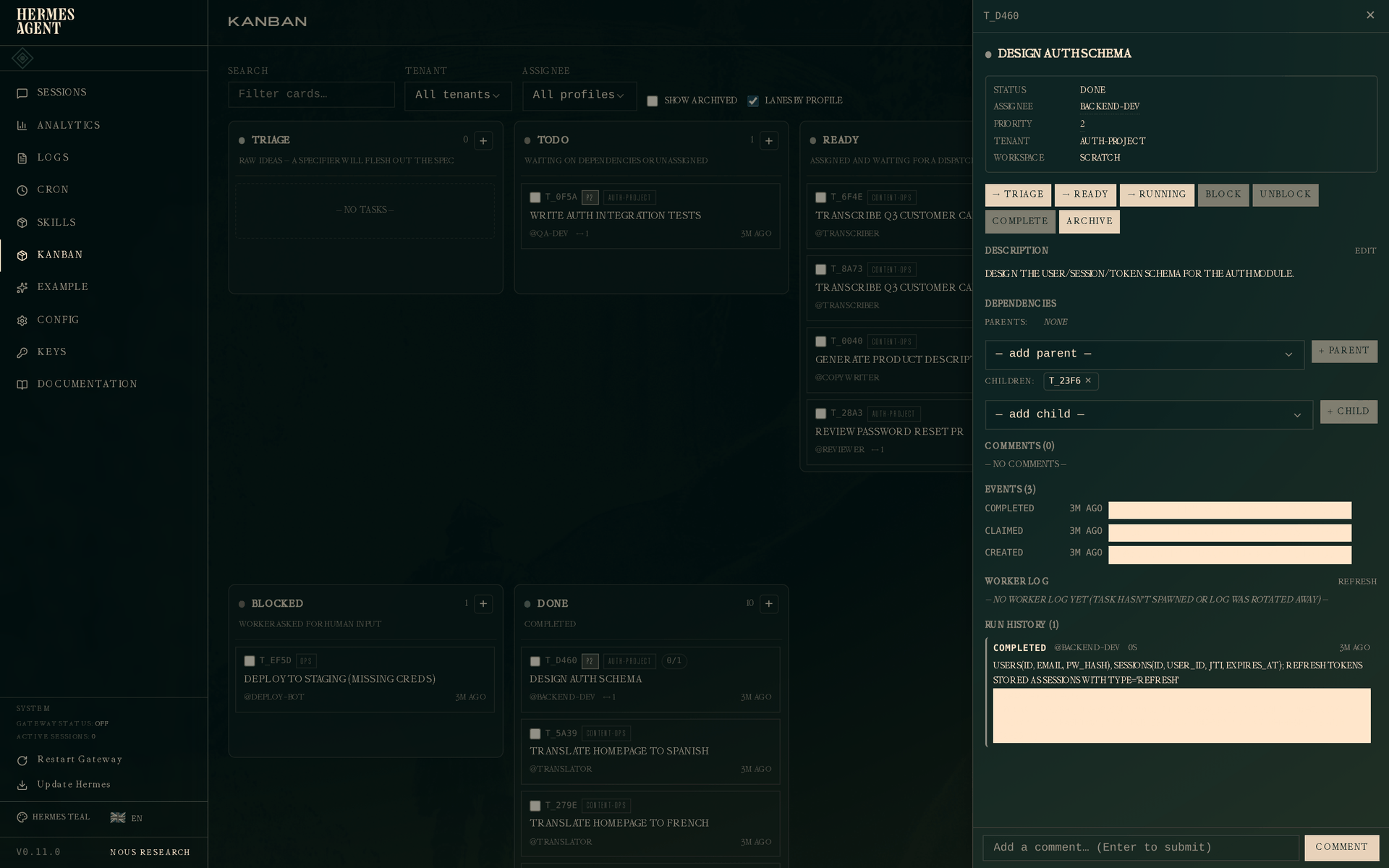
底部的 Run History 部分是关键新增内容。一次尝试:结果 completed,worker @backend-dev,耗时、时间戳,以及完整的交接 summary。metadata 块(changed_files、decisions)也存储在 run 上,并会呈现给读取该父任务的任何下游 worker。
你可以随时在终端检查相同的数据——以下命令是你查看看板,而非 worker 执行:
aigenlabs kanban show $SCHEMA
aigenlabs kanban runs $SCHEMA
# # OUTCOME PROFILE ELAPSED STARTED
# 1 completed backend-dev 0s 2026-04-27 19:34
# → users(id, email, pw_hash), sessions(id, user_id, jti, expires_at); refresh tokens ...
场景二 — 集群并行处理
你有三个 worker(翻译员、转录员、文案撰写员)和一批相互独立的任务。你希望三者并行拉取任务并产生可见进展。这是最简单的 kanban 使用场景,也是最初设计所优化的场景。
创建工作任务:
for lang in Spanish French German; do
aigenlabs kanban create "Translate homepage to $lang" \
--assignee translator --tenant content-ops
done
for i in 1 2 3 4 5; do
aigenlabs kanban create "Transcribe Q3 customer call #$i" \
--assignee transcriber --tenant content-ops
done
for sku in 1001 1002 1003 1004; do
aigenlabs kanban create "Generate product description: SKU-$sku" \
--assignee copywriter --tenant content-ops
done
启动 gateway 然后离开——它托管内嵌的 dispatcher, 在同一个 kanban.db 上处理三个专家 profile 的任务:
aigenlabs gateway start
现在将看板筛选到 content-ops(或直接搜索"Transcribe"),你会看到:
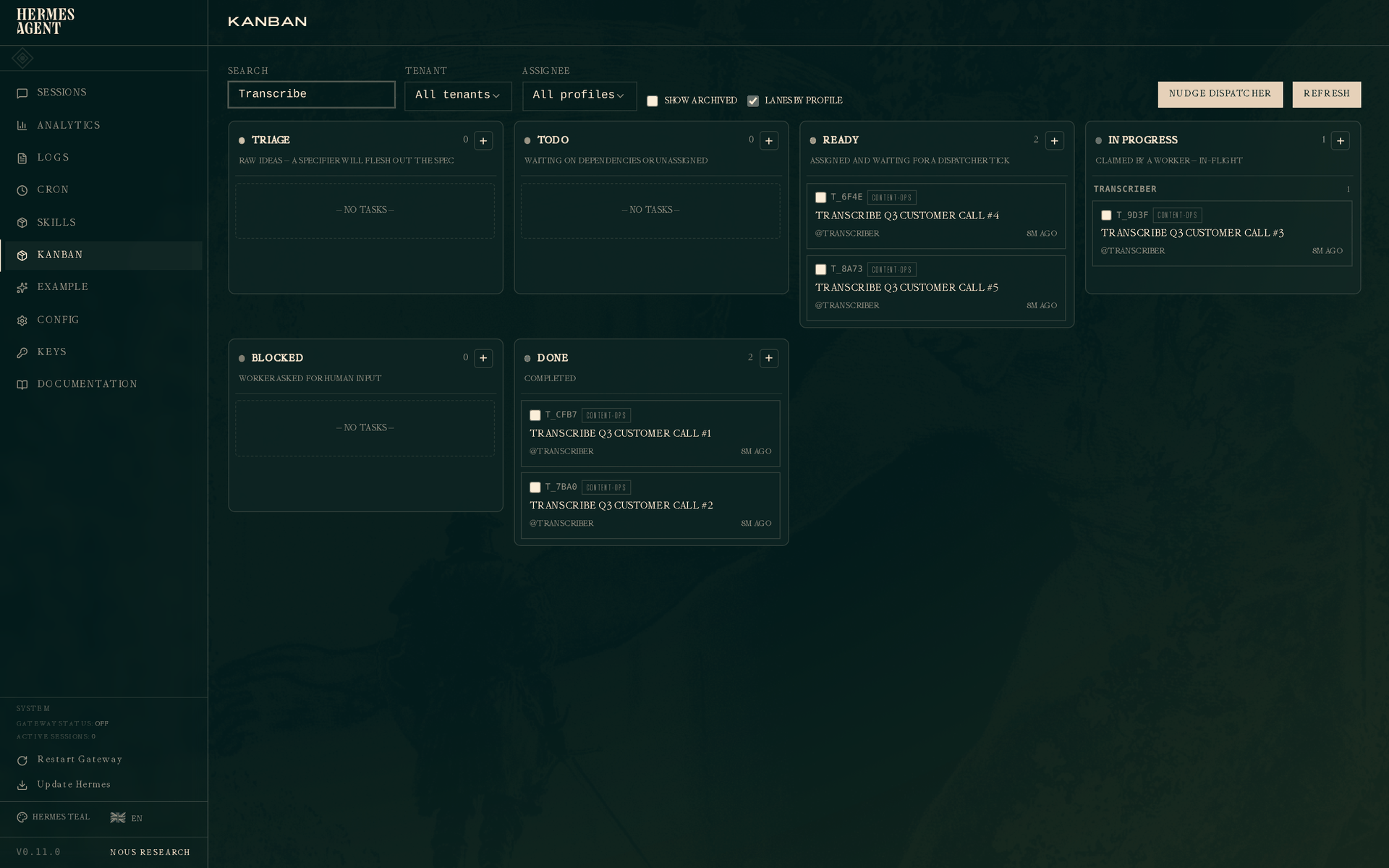
两个转录任务已完成,一个正在运行,两个就绪等待下一次 dispatcher tick。In Progress 列按 profile 分组("Lanes by profile"默认开启),让你无需扫描混合列表即可看到每个 worker 的当前任务。dispatcher 会在当前任务完成后立即将下一个就绪任务提升为运行中。三个守护进程并行处理三个负责人池,整个内容队列无需进一步人工干预即可清空。
场景一中关于结构化交接的所有内容在这里同样适用。 完成一次通话的翻译 worker 会发出 kanban_complete(summary="translated 4 pages, style matched existing marketing voice", metadata={"duration_seconds": 720, "tokens_used": 2100})——对分析以及依赖此任务的任何下游任务都很有价值。
场景三 — 角色流水线与重试
这正是 Kanban 相比普通 TODO 列表的价值所在。PM 编写规格说明,工程师实现,审查者拒绝第一次尝试,工程师修改后再次尝试,审查者批准。
dashboard 视图,按 auth-project 筛选:
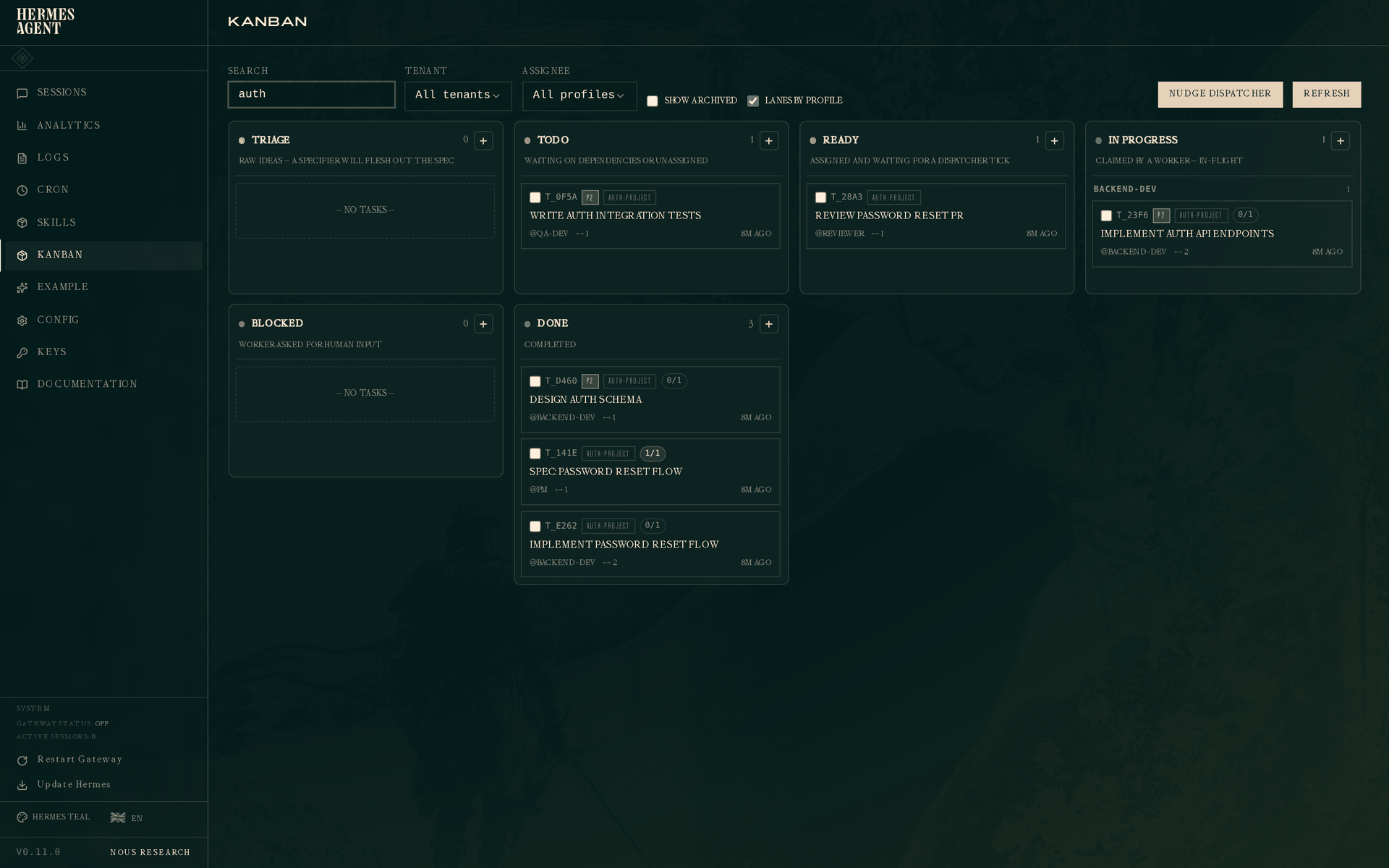
三个阶段的链条一目了然:Spec: password reset flow(DONE,pm)、Implement password reset flow(DONE,backend-dev)、Review password reset PR(READY,reviewer)。每个任务底部都有绿色的父任务,以及作为依赖项的子任务。
最有趣的是实现任务,因为它经历了阻塞和重试。以下是完整的三 agent 协作流程,以每个 worker 模型发出的工具调用形式展示:
# --- PM worker 在 $SPEC 上生成并编写验收标准 ---
# worker tool calls
kanban_show()
kanban_complete(
summary="spec approved; POST /forgot-password sends email, "
"GET /reset/:token renders form, POST /reset applies new password",
metadata={"acceptance": [
"expired token returns 410",
"reused last-3 password returns 400 with message",
"successful reset invalidates all active sessions",
]},
)
# → $SPEC 完成;$IMPL 自动从 todo 提升为 ready
# --- 工程师 worker 在 $IMPL 上生成(第一次尝试)---
# worker tool calls
kanban_show() # 在 worker_context 中读取 $SPEC 的 summary 和 acceptance metadata
# (工程师编写代码,运行测试,开启 PR)
# 审查者反馈到来——工程师认为问题有效并阻塞任务
kanban_block(
reason="Review: password strength check missing, reset link isn't "
"single-use (can be replayed within 30min)",
)
# → $IMPL 转换为 blocked;run 1 以 outcome='blocked' 关闭
现在你(人类,或单独的 reviewer profile)读取阻塞原因,判断修复方向明确,从 dashboard 的"Unblock"按钮解除阻塞——或通过 CLI/斜杠命令:
aigenlabs kanban unblock $IMPL
# 或在聊天中:/kanban unblock $IMPL
dispatcher 将 $IMPL 提升回 ready,并在下一次 tick 时重新生成 backend-dev worker。这第二次生成是同一任务上的新 run:
# --- 工程师 worker 在 $IMPL 上生成(第二次尝试)---
# worker tool calls
kanban_show()
# → worker_context 现在包含 run 1 的阻塞原因,因此该 worker 知道
# 需要修复哪两个问题,而无需重新阅读整个规格说明
# (工程师添加 zxcvbn 检查,使重置令牌变为一次性,重新运行测试)
kanban_complete(
summary="added zxcvbn strength check, reset tokens are now single-use "
"(stored + deleted on success)",
metadata={
"changed_files": [
"auth/reset.py",
"auth/tests/test_reset.py",
"migrations/003_single_use_reset_tokens.sql",
],
"tests_run": 11,
"review_iteration": 2,
},
)
点击实现任务,抽屉显示两次尝试:
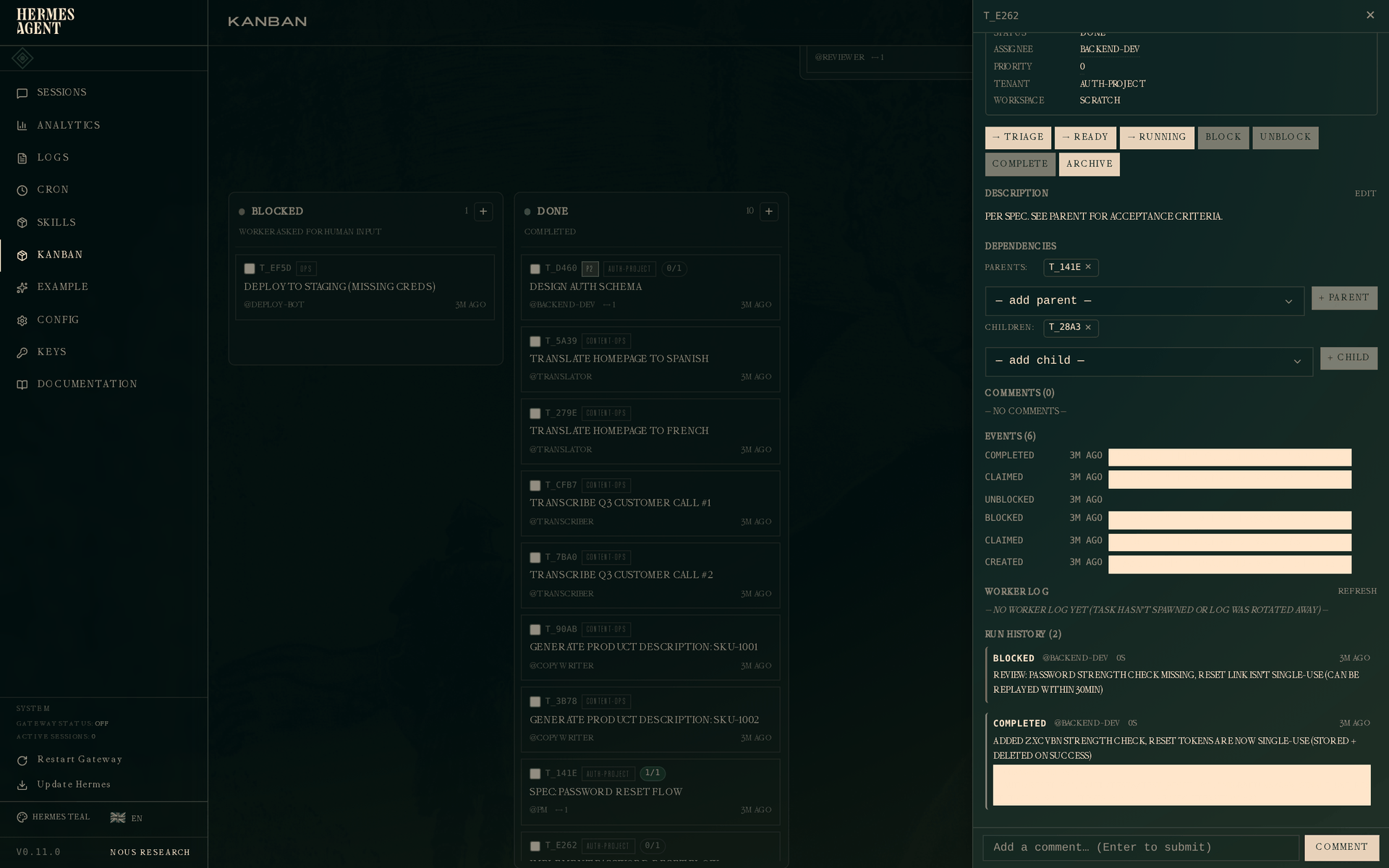
- Run 1 —
@backend-dev标记为blocked。审查反馈紧跟在结果下方:"password strength check missing, reset link isn't single-use (can be replayed within 30min)"。 - Run 2 —
@backend-dev标记为completed。全新的 summary,全新的 metadata。
每个 run 在 task_runs 中都是独立的一行,有自己的 outcome、summary 和 metadata。重试历史不是叠加在"最新状态"任务之上的概念性附加物——它是主要的数据表示形式。当重试的 worker 打开任务时,build_worker_context 会向其展示之前的尝试,因此第二次 worker 能看到第一次被阻塞的原因,并针对性地解决那些具体问题,而不是从头重来。
审查者接下来认领任务。当他们打开 Review password reset PR 时,会看到:
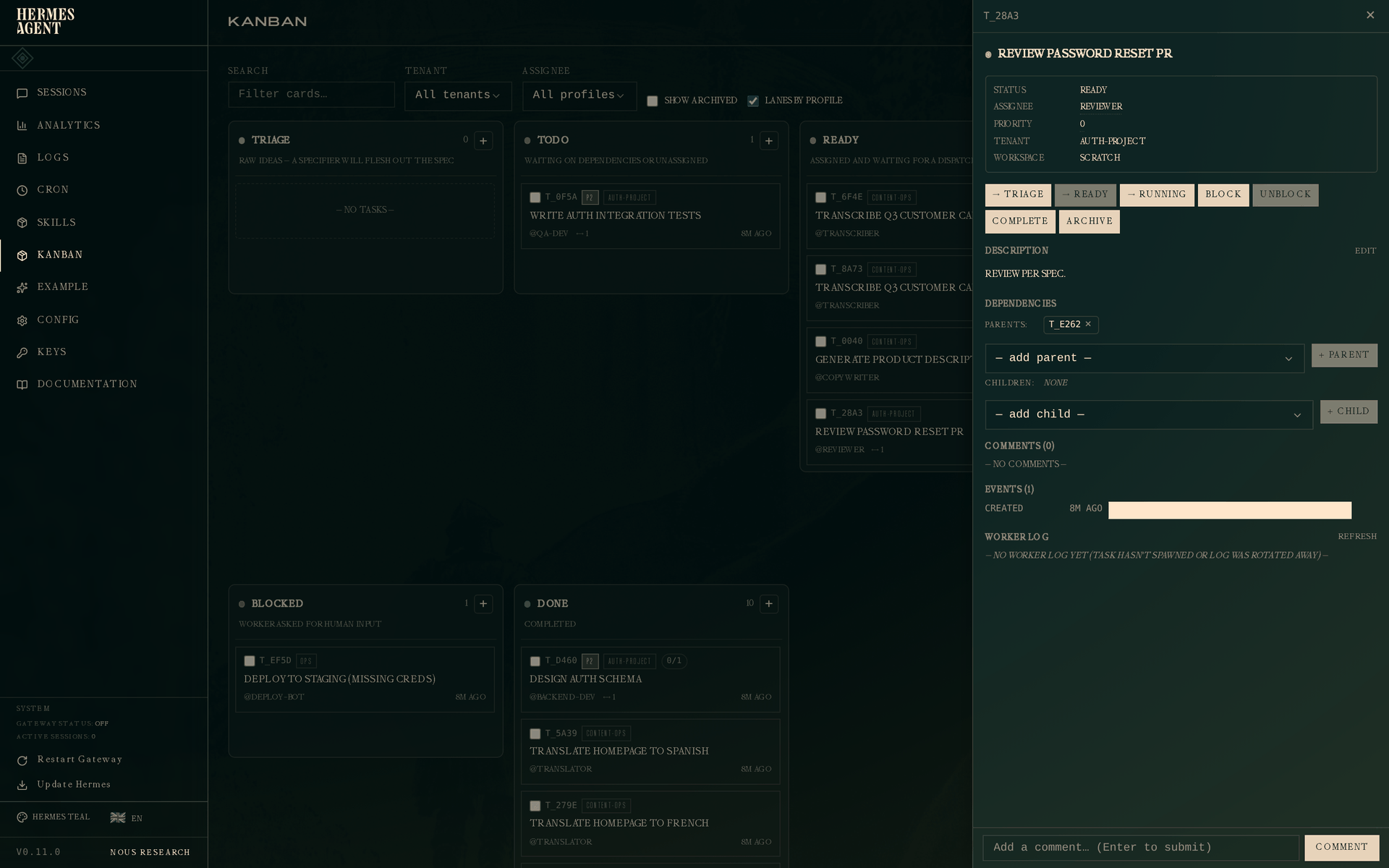
父任务链接指向已完成的实现任务。当审查者的 worker 在 Review password reset PR 上生成并调用 kanban_show() 时,返回的 worker_context 包含父任务最近一次已完成 run 的 summary 和 metadata——因此审查者在查看 diff 之前就已读到"added zxcvbn strength check, reset tokens are now single-use",并掌握了变更文件列表。
场景四 — 熔断器与崩溃恢复
真实的 worker 会失败。缺少凭证、OOM 终止、瞬时网络错误。dispatcher 有两道防线:熔断器(circuit breaker)在连续 N 次失败后自动阻塞任务,防止看板无限抖动;崩溃检测(crash detection)在 worker PID 于 TTL 到期前消失时回收任务。
熔断器 — 持续性失败
一个因 profile 环境中未设置 AWS_ACCESS_KEY_ID 而无法生成 worker 的部署任务:
aigenlabs kanban create "Deploy to staging (missing creds)" \
--assignee deploy-bot --tenant ops \
--max-retries 3
dispatcher 尝试生成 worker。生成失败(RuntimeError: AWS_ACCESS_KEY_ID not set)。dispatcher 释放认领,递增失败计数器,并在下一次 tick 重试。由于本示例设置了 --max-retries 3,在三次连续失败后熔断器触发:任务进入 blocked 状态,outcome 为 gave_up。如果省略该标志,AigenLabs 使用 kanban.failure_limit(默认值:2)。在人工解除阻塞之前不再重试。
点击被阻塞的任务:
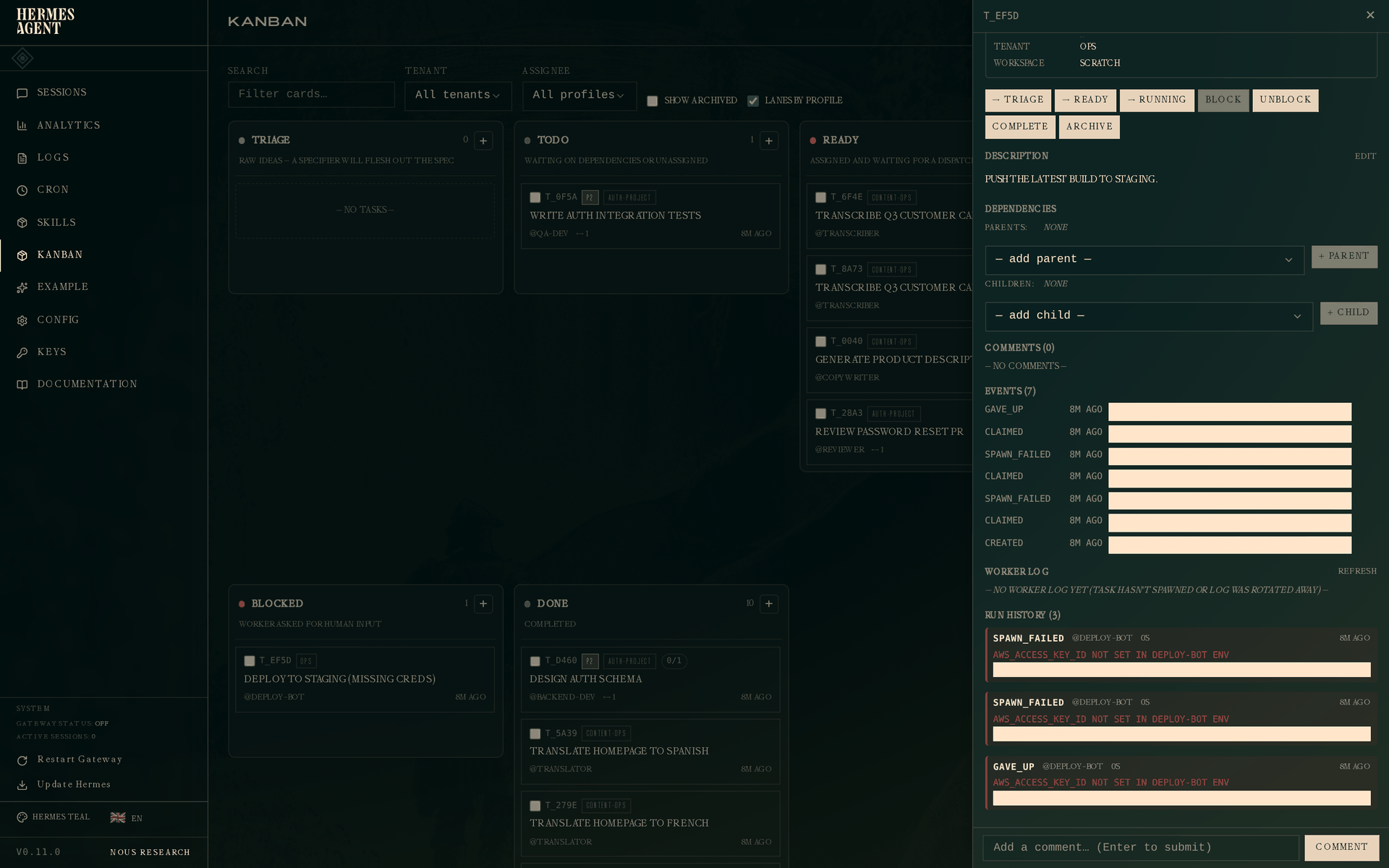
三个 run,error 字段均为相同错误。前两个为 spawn_failed(可重试),第三个为 gave_up(终止)。上方的事件日志显示完整序列:created → claimed → spawn_failed → claimed → spawn_failed → claimed → gave_up。
在终端:
aigenlabs kanban runs t_ef5d
# # OUTCOME PROFILE ELAPSED STARTED
# 1 spawn_failed deploy-bot 0s 2026-04-27 19:34
# ! AWS_ACCESS_KEY_ID not set in deploy-bot env
# 2 spawn_failed deploy-bot 0s 2026-04-27 19:34
# ! AWS_ACCESS_KEY_ID not set in deploy-bot env
# 3 gave_up deploy-bot 0s 2026-04-27 19:34
# ! AWS_ACCESS_KEY_ID not set in deploy-bot env
如果接入了 Telegram/Discord/Slack,gateway 会在 gave_up 事件时发送通知,让你无需主动检查看板就能得知故障。
崩溃恢复 — worker 在运行中途死亡
有时生成成功,但 worker 进程在之后死亡——段错误、OOM、systemctl stop。dispatcher 轮询 kill(pid, 0) 检测到死亡的 pid;认领释放,任务回到 ready,下一次 tick 将其分配给新的 worker。
种子数据中的示例是一个因内存不足而运行失败的迁移任务:
# Worker 认领,开始扫描 240 万行,在约 230 万行时被 OOM 终止
# Dispatcher 检测到死亡的 pid,释放认领,递增尝试计数器
# 使用分块策略重试成功
抽屉显示完整的两次尝试历史:
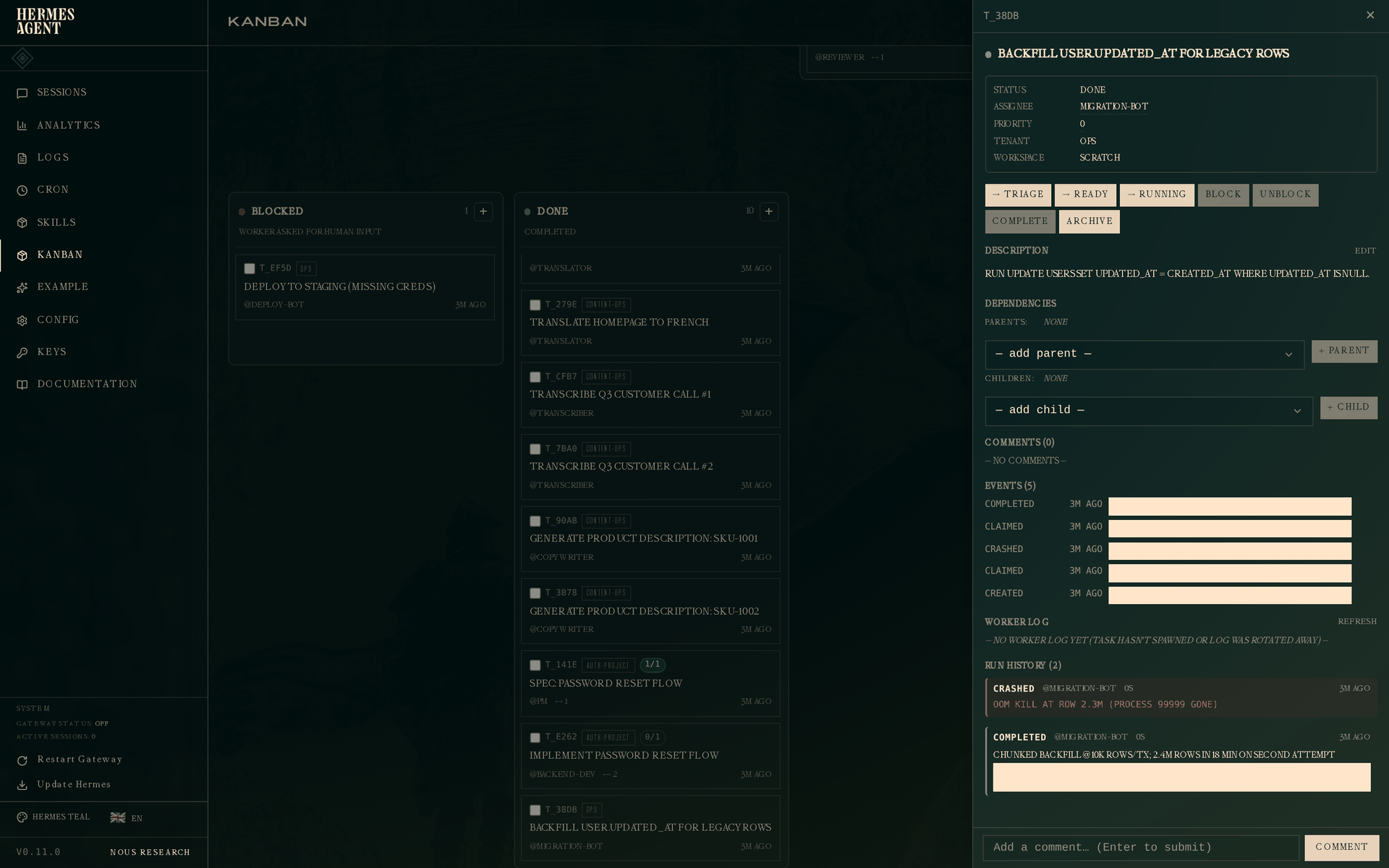
Run 1 — crashed,错误为 OOM kill at row 2.3M (process 99999 gone)。Run 2 — completed,metadata 中包含 "strategy": "chunked with LIMIT + WHERE id > last_id"。重试的 worker 在其上下文中看到了 run 1 的崩溃信息,并选择了更安全的策略;metadata 让未来的观察者(或事后分析撰写者)能清楚地看到发生了什么变化。
结构化交接 — summary 和 metadata 的重要性
在上述每个场景中,worker 在结束时都调用了 kanban_complete(summary=..., metadata=...)。这不是装饰性的——它是工作流各阶段之间的主要交接通道。
当任务 B 上的 worker 被生成并调用 kanban_show() 时,返回的 worker_context 包含:
- B 的先前尝试(之前的 run:outcome、summary、error、metadata),让重试的 worker 不会重蹈失败的路径。
- 父任务结果 — 对于每个父任务,最近一次已完成 run 的 summary 和 metadata——让下游 worker 能看到上游工作的原因和方式。
这取代了平面 kanban 系统中"翻查评论和工作输出"的繁琐流程。PM 在规格说明的 metadata 中编写验收标准,工程师的 worker 在父任务交接中以结构化形式看到它们。工程师记录运行了哪些测试以及通过了多少,审查者的 worker 在打开 diff 之前就已掌握该列表。
批量关闭保护的存在正是因为这些数据是按 run 存储的。aigenlabs kanban complete a b c --summary X(你,从 CLI 执行)会被拒绝——将相同的 summary 复制粘贴到三个任务几乎总是错误的。不带交接标志的批量关闭仍然适用于常见的"我完成了一堆行政任务"场景。工具界面根本不提供批量变体;kanban_complete 始终是单任务操作,原因相同。
检查当前正在运行的任务
作为补充——以下是一个仍在执行中的任务的抽屉视图(场景一中的 API 实现,已被 backend-dev 认领但尚未完成):
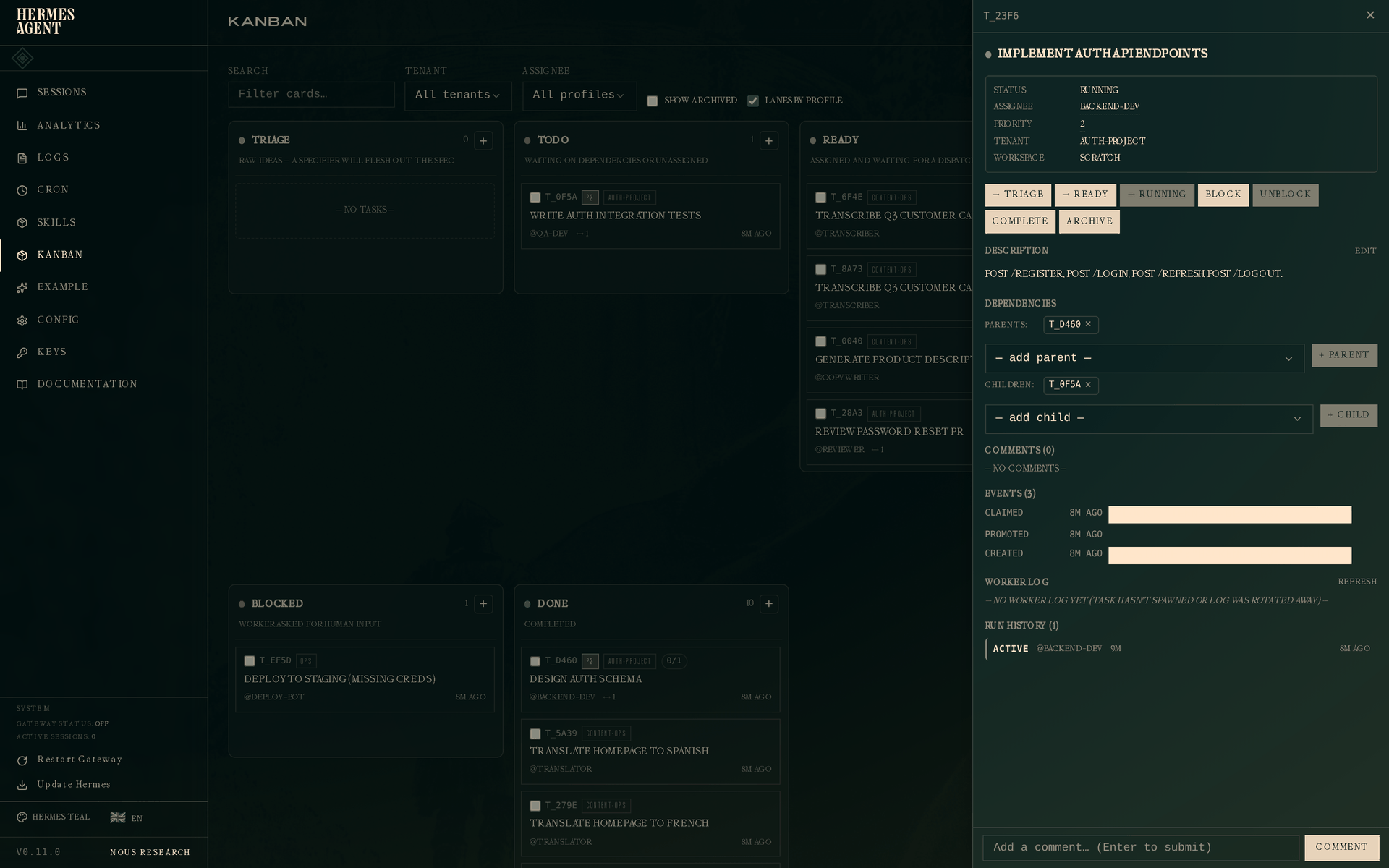
状态为 Running。活跃的 run 出现在 Run History 部分,outcome 为 active,没有 ended_at。如果该 worker 死亡或超时,dispatcher 会以相应的 outcome 关闭此 run,并在下一次认领时开启新的 run——尝试记录永远不会消失。
后续步骤
- Kanban 概述 — 完整的数据模型、事件词汇表和 CLI 参考。
aigenlabs kanban --help— 所有子命令,所有标志。aigenlabs kanban watch --kinds completed,gave_up,timed_out— 在整个看板上实时流式输出终端事件。aigenlabs kanban notify-subscribe <task> --platform telegram --chat-id <id>— 当特定任务完成时通过 gateway 接收推送通知。